데이터 처리를 하다보면 컬럼 값(데이터 도메인)에 따라 데이터 조작이 필요한 경우가 많습니다.
예를 들면, 월 별 N일 전 판매량에 대한 컬럼을 추가해야 한다던지, 전 일 기준 2주 이동 평균을 나타내야 하는 경우가 있을텐데요 :(
파이썬에서는 그럴 때 "groupby"와 "shift" 함수를 동시에 이용하여 작업할 수 있어요.
예를 들어, 아래와 같이 영화의 일자별 좌석 판매율 데이터가 있다고 가정해볼까요?

여기서 영화별 좌석판매율 컬럼을 2칸씩 아래로 내리는 작업이 필요하다고 한다면
dataset["좌석판매율_shift"] = dataset.sort_values(by=["영화명", "일자"], ascending=False).groupby("영화명")["좌석판매율"].shift(-2, fill_value = 0)
위와 같이 DataFrame의 groupby와 shift 함수를 이용하여 코딩할 수 있어요.
이 구문을 하나하나 설명하면 DataFrame한테 다음과 같이 명령한 것인데요.
1) 목적에 맞게 sort_values 함수를 통해 정리 한 후,
2) groupby로 기준이 되는 컬럼을 선정해줄래?
3) 그 후, shift 함수를 통해서 2칸씩 이동해주라
그 결과,
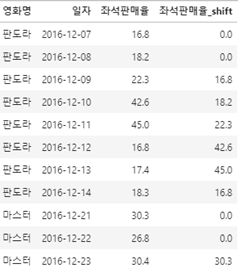
2일을 이동하게 되면 기존에 있던 날짜에는 NaN 값이 들어가게 되요.
제가 작성한 코드에는 fill_value 옵션을 0으로 설정하여 NaN값을 채웠습니다.
필요 시 비즈니스 환경에 맞게 값을 채워넣으면 좋을 것 같네요.
그럼 여기까지 DataFrame의 컬럼의 그룹별 데이터 shift하는 방법을 정리했습니다:)
'즐거운, 즐겁게 > Pandas' 카테고리의 다른 글
| DataFrame 특정 컬럼명 수정, 전체 컬럼명 수정하는 방법 (0) | 2021.05.23 |
|---|---|
| 2개의 파이썬 리스트에 공통 원소 빼는 방법 (0) | 2021.05.23 |
| 주피터노트북, 주피터랩에서 DataFrame 컬럼 및 로우 범위 늘리기 (0) | 2021.05.19 |
| Pandas를 이용한 Pivot Table 만들기 (0) | 2021.05.19 |
| pickle과 joblib을 이용하여 모델 저장하는 법 (0) | 2021.05.19 |
